SQLAlchemy 0.6 Documentation
Engine Configuration¶
The Engine is the starting point for any SQLAlchemy application. It’s “home base” for the actual database and its DBAPI, delivered to the SQLAlchemy application through a connection pool and a Dialect, which describes how to talk to a specific kind of database/DBAPI combination.
The general structure can be illustrated as follows:
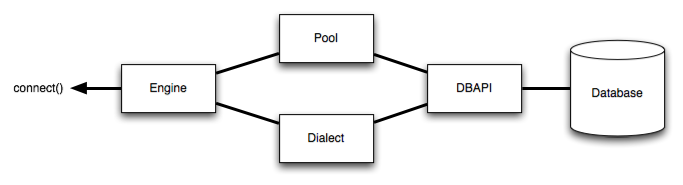
Where above, an Engine references both a Dialect and a Pool, which together interpret the DBAPI’s module functions as well as the behavior of the database.
Creating an engine is just a matter of issuing a single call, create_engine():
from sqlalchemy import create_engine
engine = create_engine('postgresql://scott:tiger@localhost:5432/mydatabase')The above engine creates a Dialect object tailored towards PostgreSQL, as well as a Pool object which will establish a DBAPI connection at localhost:5432 when a connection request is first received. Note that the Engine and its underlying Pool do not establish the first actual DBAPI connection until the Engine.connect() method is called, or an operation which is dependent on this method such as Engine.execute() is invoked. In this way, Engine and Pool can be said to have a lazy initialization behavior.
The Engine, once created, can either be used directly to interact with the database, or can be passed to a Session object to work with the ORM. This section covers the details of configuring an Engine. The next section, Working with Engines and Connections, will detail the usage API of the Engine and similar, typically for non-ORM applications.
Supported Databases¶
SQLAlchemy includes many Dialect implementations for various backends; each is described as its own package in the sqlalchemy.dialects_toplevel package. A SQLAlchemy dialect always requires that an appropriate DBAPI driver is installed.
The table below summarizes the state of DBAPI support in SQLAlchemy 0.6. The values translate as:
- yes / Python platform - The SQLAlchemy dialect is mostly or fully operational on the target platform.
- yes / OS platform - The DBAPI supports that platform.
- no / Python platform - The DBAPI does not support that platform, or there is no SQLAlchemy dialect support.
- no / OS platform - The DBAPI does not support that platform.
- partial - the DBAPI is partially usable on the target platform but has major unresolved issues.
- development - a development version of the dialect exists, but is not yet usable.
- thirdparty - the dialect itself is maintained by a third party, who should be consulted for information on current support.
- * - indicates the given DBAPI is the “default” for SQLAlchemy, i.e. when just the database name is specified
| Driver | Connect string | Py2K | Py3K | Jython | Unix | Windows |
|---|---|---|---|---|---|---|
| DB2/Informix IDS | ||||||
| ibm-db | thirdparty | thirdparty | thirdparty | thirdparty | thirdparty | thirdparty |
| Firebird | ||||||
| kinterbasdb | firebird+kinterbasdb* | yes | development | no | yes | yes |
| Informix | ||||||
| informixdb | informix+informixdb* | yes | development | no | unknown | unknown |
| MaxDB | ||||||
| sapdb | maxdb+sapdb* | development | development | no | yes | unknown |
| Microsoft Access | ||||||
| pyodbc | access+pyodbc* | development | development | no | unknown | yes |
| Microsoft SQL Server | ||||||
| adodbapi | mssql+adodbapi | development | development | no | no | yes |
| jTDS JDBC Driver | mssql+zxjdbc | no | no | development | yes | yes |
| mxodbc | mssql+mxodbc | yes | development | no | yes with FreeTDS | yes |
| pyodbc | mssql+pyodbc* | yes | development | no | yes with FreeTDS | yes |
| pymssql | mssql+pymssql | yes | development | no | yes | yes |
| MySQL | ||||||
| MySQL Connector/J | mysql+zxjdbc | no | no | yes | yes | yes |
| MySQL Connector/Python | mysql+mysqlconnector | yes | development | no | yes | yes |
| mysql-python | mysql+mysqldb* | yes | development | no | yes | yes |
| OurSQL | mysql+oursql | yes | yes | no | yes | yes |
| Oracle | ||||||
| cx_oracle | oracle+cx_oracle* | yes | development | no | yes | yes |
| Oracle JDBC Driver | oracle+zxjdbc | no | no | yes | yes | yes |
| Postgresql | ||||||
| pg8000 | postgresql+pg8000 | yes | yes | no | yes | yes |
| PostgreSQL JDBC Driver | postgresql+zxjdbc | no | no | yes | yes | yes |
| psycopg2 | postgresql+psycopg2* | yes | development | no | yes | yes |
| pypostgresql | postgresql+pypostgresql | no | yes | no | yes | yes |
| SQLite | ||||||
| pysqlite | sqlite+pysqlite* | yes | yes | no | yes | yes |
| sqlite3 | sqlite+pysqlite* | yes | yes | no | yes | yes |
| Sybase ASE | ||||||
| mxodbc | sybase+mxodbc | development | development | no | yes | yes |
| pyodbc | sybase+pyodbc* | partial | development | no | unknown | unknown |
| python-sybase | sybase+pysybase | yes [1] | development | no | yes | yes |
| [1] | The Sybase dialect currently lacks the ability to reflect tables. |
Further detail on dialects is available at Dialects.
Database Engine Options¶
Keyword options can also be specified to create_engine(), following the string URL as follows:
db = create_engine('postgresql://...', encoding='latin1', echo=True)- sqlalchemy.create_engine(*args, **kwargs)¶
Create a new Engine instance.
The standard calling form is to send the URL as the first positional argument, usually a string that indicates database dialect and connection arguments. Additional keyword arguments may then follow it which establish various options on the resulting Engine and its underlying Dialect and Pool constructs.
The string form of the URL is dialect+driver://user:password@host/dbname[?key=value..], where dialect is a database name such as mysql, oracle, postgresql, etc., and driver the name of a DBAPI, such as psycopg2, pyodbc, cx_oracle, etc. Alternatively, the URL can be an instance of URL.
**kwargs takes a wide variety of options which are routed towards their appropriate components. Arguments may be specific to the Engine, the underlying Dialect, as well as the Pool. Specific dialects also accept keyword arguments that are unique to that dialect. Here, we describe the parameters that are common to most create_engine() usage.
Once established, the newly resulting Engine will request a connection from the underlying Pool once Engine.connect() is called, or a method which depends on it such as Engine.execute() is invoked. The Pool in turn will establish the first actual DBAPI connection when this request is received. The create_engine() call itself does not establish any actual DBAPI connections directly.
Parameters: - assert_unicode – Deprecated. A warning is raised in all cases when a non-Unicode object is passed when SQLAlchemy would coerce into an encoding (note: but not when the DBAPI handles unicode objects natively). To suppress or raise this warning to an error, use the Python warnings filter documented at: http://docs.python.org/library/warnings.html
- connect_args – a dictionary of options which will be passed directly to the DBAPI’s connect() method as additional keyword arguments.
- convert_unicode=False – if set to True, all String/character based types will convert Python Unicode values to raw byte values sent to the DBAPI as bind parameters, and all raw byte values to Python Unicode coming out in result sets. This is an engine-wide method to provide Unicode conversion across the board for those DBAPIs that do not accept Python Unicode objects as input. For Unicode conversion on a column-by-column level, use the Unicode column type instead, described in Column and Data Types. Note that many DBAPIs have the ability to return Python Unicode objects in result sets directly - SQLAlchemy will use these modes of operation if possible and will also attempt to detect “Unicode returns” behavior by the DBAPI upon first connect by the Engine. When this is detected, string values in result sets are passed through without further processing.
- creator – a callable which returns a DBAPI connection. This creation function will be passed to the underlying connection pool and will be used to create all new database connections. Usage of this function causes connection parameters specified in the URL argument to be bypassed.
- echo=False – if True, the Engine will log all statements as well as a repr() of their parameter lists to the engines logger, which defaults to sys.stdout. The echo attribute of Engine can be modified at any time to turn logging on and off. If set to the string "debug", result rows will be printed to the standard output as well. This flag ultimately controls a Python logger; see Configuring Logging for information on how to configure logging directly.
- echo_pool=False – if True, the connection pool will log all checkouts/checkins to the logging stream, which defaults to sys.stdout. This flag ultimately controls a Python logger; see Configuring Logging for information on how to configure logging directly.
- encoding=’utf-8’ – the encoding to use for all Unicode translations, both by engine-wide unicode conversion as well as the Unicode type object.
- execution_options – Dictionary execution options which will be applied to all connections. See execution_options()
- implicit_returning=True – When True, a RETURNING- compatible construct, if available, will be used to fetch newly generated primary key values when a single row INSERT statement is emitted with no existing returning() clause. This applies to those backends which support RETURNING or a compatible construct, including Postgresql, Firebird, Oracle, Microsoft SQL Server. Set this to False to disable the automatic usage of RETURNING.
- label_length=None – optional integer value which limits the size of dynamically generated column labels to that many characters. If less than 6, labels are generated as “_(counter)”. If None, the value of dialect.max_identifier_length is used instead.
- listeners – A list of one or more PoolListener objects which will receive connection pool events.
- logging_name – String identifier which will be used within the “name” field of logging records generated within the “sqlalchemy.engine” logger. Defaults to a hexstring of the object’s id.
- max_overflow=10 – the number of connections to allow in connection pool “overflow”, that is connections that can be opened above and beyond the pool_size setting, which defaults to five. this is only used with QueuePool.
- module=None – reference to a Python module object (the module itself, not its string name). Specifies an alternate DBAPI module to be used by the engine’s dialect. Each sub-dialect references a specific DBAPI which will be imported before first connect. This parameter causes the import to be bypassed, and the given module to be used instead. Can be used for testing of DBAPIs as well as to inject “mock” DBAPI implementations into the Engine.
- pool=None – an already-constructed instance of Pool, such as a QueuePool instance. If non-None, this pool will be used directly as the underlying connection pool for the engine, bypassing whatever connection parameters are present in the URL argument. For information on constructing connection pools manually, see Connection Pooling.
- poolclass=None – a Pool subclass, which will be used to create a connection pool instance using the connection parameters given in the URL. Note this differs from pool in that you don’t actually instantiate the pool in this case, you just indicate what type of pool to be used.
- pool_logging_name – String identifier which will be used within the “name” field of logging records generated within the “sqlalchemy.pool” logger. Defaults to a hexstring of the object’s id.
- pool_size=5 – the number of connections to keep open inside the connection pool. This used with QueuePool as well as SingletonThreadPool. With QueuePool, a pool_size setting of 0 indicates no limit; to disable pooling, set poolclass to NullPool instead.
- pool_recycle=-1 – this setting causes the pool to recycle connections after the given number of seconds has passed. It defaults to -1, or no timeout. For example, setting to 3600 means connections will be recycled after one hour. Note that MySQL in particular will disconnect automatically if no activity is detected on a connection for eight hours (although this is configurable with the MySQLDB connection itself and the server configuration as well).
- pool_timeout=30 – number of seconds to wait before giving up on getting a connection from the pool. This is only used with QueuePool.
- strategy=’plain’ – selects alternate engine implementations. Currently available is the threadlocal strategy, which is described in Using the Threadlocal Execution Strategy.
- sqlalchemy.engine_from_config(configuration, prefix='sqlalchemy.', **kwargs)¶
Create a new Engine instance using a configuration dictionary.
The dictionary is typically produced from a config file where keys are prefixed, such as sqlalchemy.url, sqlalchemy.echo, etc. The ‘prefix’ argument indicates the prefix to be searched for.
A select set of keyword arguments will be “coerced” to their expected type based on string values. In a future release, this functionality will be expanded and include dialect-specific arguments.
Database Urls¶
SQLAlchemy indicates the source of an Engine strictly via RFC-1738 style URLs, combined with optional keyword arguments to specify options for the Engine. The form of the URL is:
dialect+driver://username:password@host:port/database
Dialect names include the identifying name of the SQLAlchemy dialect which include sqlite, mysql, postgresql, oracle, mssql, and firebird. The drivername is the name of the DBAPI to be used to connect to the database using all lowercase letters. If not specified, a “default” DBAPI will be imported if available - this default is typically the most widely known driver available for that backend (i.e. cx_oracle, pysqlite/sqlite3, psycopg2, mysqldb). For Jython connections, specify the zxjdbc driver, which is the JDBC-DBAPI bridge included with Jython.
# postgresql - psycopg2 is the default driver.
pg_db = create_engine('postgresql://scott:tiger@localhost/mydatabase')
pg_db = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
pg_db = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')
pg_db = create_engine('postgresql+pypostgresql://scott:tiger@localhost/mydatabase')
# postgresql on Jython
pg_db = create_engine('postgresql+zxjdbc://scott:tiger@localhost/mydatabase')
# mysql - MySQLdb (mysql-python) is the default driver
mysql_db = create_engine('mysql://scott:tiger@localhost/foo')
mysql_db = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# mysql on Jython
mysql_db = create_engine('mysql+zxjdbc://localhost/foo')
# mysql with pyodbc (buggy)
mysql_db = create_engine('mysql+pyodbc://scott:tiger@some_dsn')
# oracle - cx_oracle is the default driver
oracle_db = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
# oracle via TNS name
oracle_db = create_engine('oracle+cx_oracle://scott:tiger@tnsname')
# mssql using ODBC datasource names. PyODBC is the default driver.
mssql_db = create_engine('mssql://mydsn')
mssql_db = create_engine('mssql+pyodbc://mydsn')
mssql_db = create_engine('mssql+adodbapi://mydsn')
mssql_db = create_engine('mssql+pyodbc://username:password@mydsn')SQLite connects to file based databases. The same URL format is used, omitting the hostname, and using the “file” portion as the filename of the database. This has the effect of four slashes being present for an absolute file path:
# sqlite://<nohostname>/<path>
# where <path> is relative:
sqlite_db = create_engine('sqlite:///foo.db')
# or absolute, starting with a slash:
sqlite_db = create_engine('sqlite:////absolute/path/to/foo.db')To use a SQLite :memory: database, specify an empty URL:
sqlite_memory_db = create_engine('sqlite://')The Engine will ask the connection pool for a connection when the connect() or execute() methods are called. The default connection pool, QueuePool, as well as the default connection pool used with SQLite, SingletonThreadPool, will open connections to the database on an as-needed basis. As concurrent statements are executed, QueuePool will grow its pool of connections to a default size of five, and will allow a default “overflow” of ten. Since the Engine is essentially “home base” for the connection pool, it follows that you should keep a single Engine per database established within an application, rather than creating a new one for each connection.
- class sqlalchemy.engine.url.URL(drivername, username=None, password=None, host=None, port=None, database=None, query=None)¶
Represent the components of a URL used to connect to a database.
This object is suitable to be passed directly to a create_engine() call. The fields of the URL are parsed from a string by the module-level make_url() function. the string format of the URL is an RFC-1738-style string.
All initialization parameters are available as public attributes.
Parameters: - drivername – the name of the database backend. This name will correspond to a module in sqlalchemy/databases or a third party plug-in.
- username – The user name.
- password – database password.
- host – The name of the host.
- port – The port number.
- database – The database name.
- query – A dictionary of options to be passed to the dialect and/or the DBAPI upon connect.
- get_dialect()¶
Return the SQLAlchemy database dialect class corresponding to this URL’s driver name.
- translate_connect_args(names=[], **kw)¶
Translate url attributes into a dictionary of connection arguments.
Returns attributes of this url (host, database, username, password, port) as a plain dictionary. The attribute names are used as the keys by default. Unset or false attributes are omitted from the final dictionary.
Parameters: - **kw – Optional, alternate key names for url attributes.
- names – Deprecated. Same purpose as the keyword-based alternate names, but correlates the name to the original positionally.
Custom DBAPI connect() arguments¶
Custom arguments used when issuing the connect() call to the underlying DBAPI may be issued in three distinct ways. String-based arguments can be passed directly from the URL string as query arguments:
db = create_engine('postgresql://scott:tiger@localhost/test?argument1=foo&argument2=bar')If SQLAlchemy’s database connector is aware of a particular query argument, it may convert its type from string to its proper type.
create_engine() also takes an argument connect_args which is an additional dictionary that will be passed to connect(). This can be used when arguments of a type other than string are required, and SQLAlchemy’s database connector has no type conversion logic present for that parameter:
db = create_engine('postgresql://scott:tiger@localhost/test', connect_args = {'argument1':17, 'argument2':'bar'})The most customizable connection method of all is to pass a creator argument, which specifies a callable that returns a DBAPI connection:
def connect():
return psycopg.connect(user='scott', host='localhost')
db = create_engine('postgresql://', creator=connect)Configuring Logging¶
Python’s standard logging module is used to implement informational and debug log output with SQLAlchemy. This allows SQLAlchemy’s logging to integrate in a standard way with other applications and libraries. The echo and echo_pool flags that are present on create_engine(), as well as the echo_uow flag used on Session, all interact with regular loggers.
This section assumes familiarity with the above linked logging module. All logging performed by SQLAlchemy exists underneath the sqlalchemy namespace, as used by logging.getLogger('sqlalchemy'). When logging has been configured (i.e. such as via logging.basicConfig()), the general namespace of SA loggers that can be turned on is as follows:
- sqlalchemy.engine - controls SQL echoing. set to logging.INFO for SQL query output, logging.DEBUG for query + result set output.
- sqlalchemy.dialects - controls custom logging for SQL dialects. See the documentation of individual dialects for details.
- sqlalchemy.pool - controls connection pool logging. set to logging.INFO or lower to log connection pool checkouts/checkins.
- sqlalchemy.orm - controls logging of various ORM functions. set to logging.INFO for information on mapper configurations.
For example, to log SQL queries using Python logging instead of the echo=True flag:
import logging
logging.basicConfig()
logging.getLogger('sqlalchemy.engine').setLevel(logging.INFO)By default, the log level is set to logging.ERROR within the entire sqlalchemy namespace so that no log operations occur, even within an application that has logging enabled otherwise.
The echo flags present as keyword arguments to create_engine() and others as well as the echo property on Engine, when set to True, will first attempt to ensure that logging is enabled. Unfortunately, the logging module provides no way of determining if output has already been configured (note we are referring to if a logging configuration has been set up, not just that the logging level is set). For this reason, any echo=True flags will result in a call to logging.basicConfig() using sys.stdout as the destination. It also sets up a default format using the level name, timestamp, and logger name. Note that this configuration has the affect of being configured in addition to any existing logger configurations. Therefore, when using Python logging, ensure all echo flags are set to False at all times, to avoid getting duplicate log lines.
The logger name of instance such as an Engine or Pool defaults to using a truncated hex identifier string. To set this to a specific name, use the “logging_name” and “pool_logging_name” keyword arguments with sqlalchemy.create_engine().
Note
The SQLAlchemy Engine conserves Python function call overhead by only emitting log statements when the current logging level is detected as logging.INFO or logging.DEBUG. It only checks this level when a new connection is procured from the connection pool. Therefore when changing the logging configuration for an already-running application, any Connection that’s currently active, or more commonly a Session object that’s active in a transaction, won’t log any SQL according to the new configuration until a new Connection is procured (in the case of Session, this is after the current transaction ends and a new one begins).